Optimise OpenAI Whisper API: Audio Format, Sampling Rate and Quality
Provides guidiance on how to reduce latency when working with the OpenAI Whisper API


While experimenting with OpenAI's Whisper model via API, I discovered it could sometimes seem slow when recognising vocal commands sent from a tool I have developed. I originally put this down to the inherent constraints of using this API, attributing it to the size of the data needing to be sent to the server - in this instance, somewhat large audio files.
However, tinkering with the format of the audio files sent to OpenAI led me to discover that response times could be optimised considerably - by over 50%, in fact. The main culprit for lag was the file size I sent through the API; i.e., the recordings requiring transcription.
By adjusting the sampling rate and quality of the content I sent to the OpenAI API, I managed to cut the file size significantly.
tldr;
It seems you can reduce latency considerably by lowering quality settings without detriment to transcription precision. Here are the settings I suggest:
- Format: MP3
- Bit Rate: 16 kbps
- Sample Rate: 12 kHz
- Channels: mono
Experiment!
I conducted a series of tests, each time recording the same command, 'Open Firefox'. The table below shows the correlated file sizes once I adjusted MP3 quality from 16 kbps through to 128 kbps and switched the sampling rate from 12k to 24k.
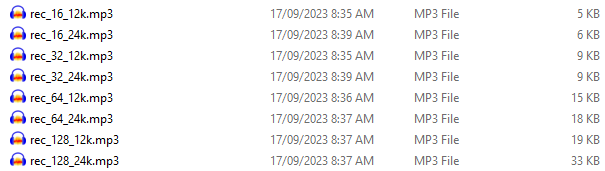
(Note: most microphones sample at 16 kHz)
I generated these recordings using fmedia with variations of the following command:
./bin/fmedia-1.31-windows-x64/fmedia/fmedia.exe --record --overwrite --mpeg-q-mpeg-quality=16 --rate=24000 --out=rec_16_24k.mp3
The results for transcription and GPT4 parsing times are as follows:
| File | Size | Time |
|---|---|---|
| rec_16_12k.mp3 | 5KB | 1.8 s |
| rec_32_12k.mp3 | 9KB | 1.8 s |
| rec_128_24k.mp3 | 33KB | 2.6 s |
I obtained these measurements via this command:
time ./bin/whisper-autohotkey/whisper-autohotkey.exe rec_16_24k.mp3
Regardless of the quality settings, the accuracy of transcription did not vary.
Conclusion
Even though my experiments are not perfect - Whisper and ChatGPT APIs are, after all, notoriously unpredictable for consumer grade accounts - the results suggest that reducing audio recording quality sent to Whisper's API can cut latency significantly without sacrificing transcription accuracy.
There seems to be little to no advantage in reducing the quality below 32 kbps and 12 kHz, possibly because of the characteristics of MP3 compression.