
javascript
Solving Jest Unexpected Token error uuid package
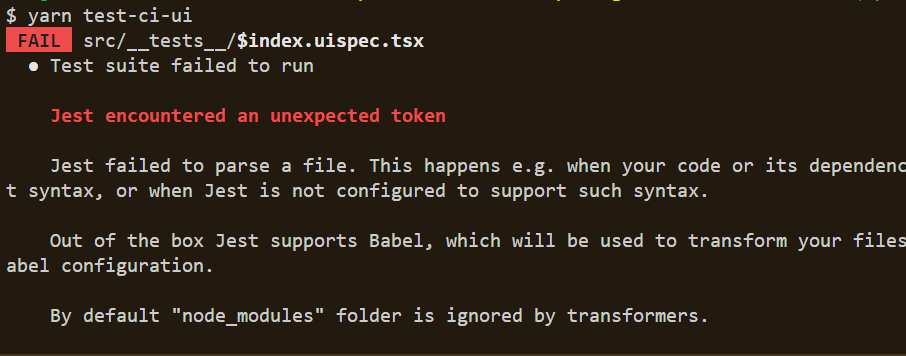
Problem When trying to run a Jest test, you encounter the following error related to the uuid package: Jest encountered an unexpected token Jest failed to parse a file. This happens e.g. when your code or its dependencies use non-standard JavaScript syntax, or when Jest is not configured to









