
esbuild
esbuild Ignore With Comments Plugin
esbuild plugin that allows ignoring specific files by adding comments into the source code.

esbuild
esbuild plugin that allows ignoring specific files by adding comments into the source code.

coding
There are many different ways to provide styling for React components, such as importing plain CSS, using styled components, JS-in-CSS or CSS Modules. These all have various advantages and disadvantages. To me, it seems CSS Modules provide the best solution overall for beginner to intermediate use. We can use the

aws
AWS HTTP APIs provides a new way to deploy REST-based APIs in AWS; providing a number of simplifications over the original REST APIs. However, when working with HTTP APIs we need to be aware of a few gotchas, such as what types to use for handler arguments. REST APIs also

aws
Amazon Simple Email Service (SES) is a serverless service for sending emails from your applications. Like other AWS services, you can send emails with SES using the AWS REST API or the AWS SDKs. In this article, I want to look at how to send emails using SES with TypeScript

aws
I has been nearly two years since I first wrote about a Next.js + Bootstrap starter project on this blog. Since then I have been extending the base template and made it easier to configure and use. It is now available as one of the templates on Goldstack: Next.js

aws
I've written a couple of posts about how to set up JavaScript and TypeScript Monorepos over the past three years (#1, #2, #3, #4, #5, #6, #7), and I kind of thought I had it all figured out - but I didn't. It turned out that

coding
As I've written in an earlier post, TypeScript project references and Yarn Workspaces are powerful tools for managing complex TypeScript projects. Yarn Workspaces manages dependencies between multiple JavaScript packages within one project, and contains tools that let us easily deduce which packages depend on which other packages in
coding
Please find an updated and extended version of this post here: The Ultimate Guide to TypeScript Monorepos. Project references in TypeScript are an amazing feature for building complex TypeScript projects. They enable dividing a large project into smaller, indepedent modules and thereby improving code organisation as well as compile times;
aws
Serverless development allows deploying low-cost, low-maintenance applications. Go is an ever-more popular language for developing backend applications. With first rate support both in AWS Lambda and GCP Cloud Functions, Go is an excellent choice for serverless development. Unfortunately, setting up a flexible infrastructure and efficient deployment pipelines for Serverless applications

aws
AWS Lambda is a cost efficient and easy way to deploy server applications. Express.js is a very popular Node.js framework that makes it very easy to develop REST APIs. This post will go through the basics of deploying an Express.js application to AWS Lambda. You can also
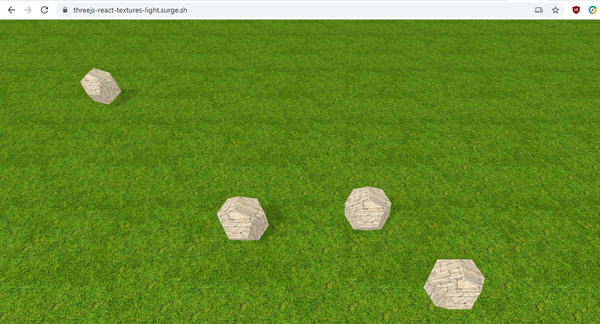
open-source
In my previous three posts, I have developed a simple WebGL application using react-three-fiber and three.js. In this post, I am adding texture loading and proper lighting to the application. For reference, here the links to the previous versions of the app: * Version 1: Just being able to drag
open-source
I have recently been working on small example application using three.js and react-three-fiber. In the first two iterations, I first developed a simple draggable shape floating in space and then supported multiple shapes that can be moved on a physical plane. In this post, I am going to be
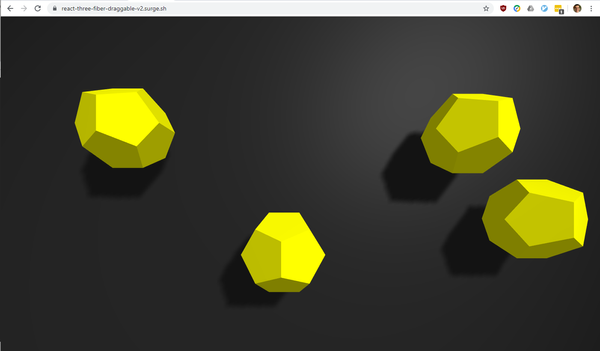
open-source
Following up from my article published a few days ago, I have now extended and improved the simple WebGL application that I originally developed using Three.js and react-three-fiber. Version 1 of the application allowed dragging a simple shape around on the screen: App: https://react-three-fiber-draggable.surge.sh/ Source Code:
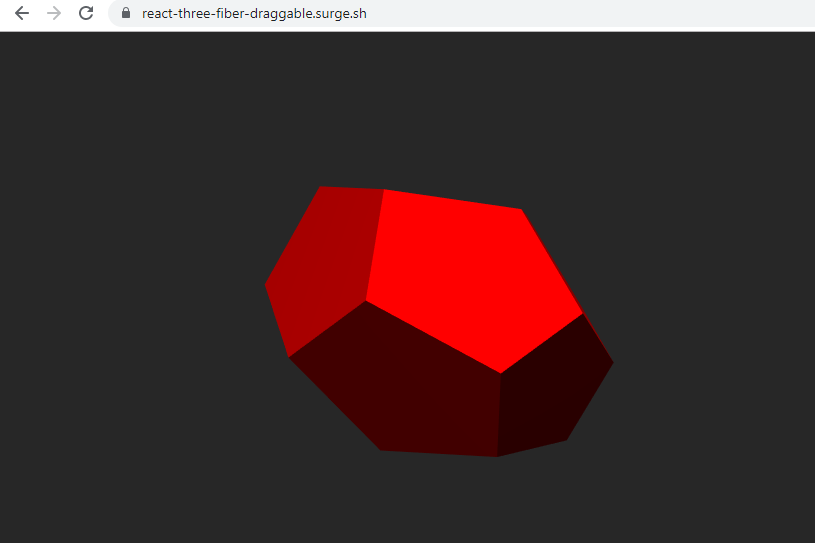
open-source
I recently became interested how to render 3D graphics in the browser. I think WebGL is an extremely powerful technology and may one day become an important way of rendering content on the web. There are various frameworks and tools available to use WebGL such as Babylon.js and three.

graphql
Following up on the GraphQL, Node.JS and React Monorepo Starter Kit and GraphQL Apollo Starter Kit (Lerna, Node.js), I have now created an extended example which includes facilities to run unit and integration tests using Jest. The code can be found on GitHub: apollo-client-server-tests The following tests are
graphql
In many ways developing in Node.js is very fast and lightweight. However it can also be bewildering at times. Mostly so since for everything there seems to be more than one established way of doing things. Moreover, the right way to do something can change within 3 to 6