
aws
Mock S3 for AWS SDK for JavaScript (v3)
Provides an npm package with a local file-based mock for S3 in the AWS JavaScript SDK (v3).

aws
Provides an npm package with a local file-based mock for S3 in the AWS JavaScript SDK (v3).

aws
Explains how to use NodeJS streaming operations when working with S3 objects in the new AWS SDK v3.

cognito
Amazon Cognito is a cloud-based, serverless solution for identity and access management. It provides similar capabilities as Auth0 and Okta. The main benefit of Cognito is that it is just another services within the AWS suite of services, and can thus easily be used if other parts of the stack

react
Explores how to implement React Server-Side Rendering (SSR) in a serverless way on AWS using a lightweight framework.

aws
AWS HTTP APIs provides a new way to deploy REST-based APIs in AWS; providing a number of simplifications over the original REST APIs. However, when working with HTTP APIs we need to be aware of a few gotchas, such as what types to use for handler arguments. REST APIs also

aws
As part of testing Goldstack templates I often create new AWS accounts and deploy a number or resources to them. Today I came across the following error while trying to stand up a CloudFront Distribution Error: error creating CloudFront Distribution: AccessDenied: Your account must be verified before you can add

aws
I have long been very sceptical of so called NoSQL databases. I believe that traditional SQL database provided better higher level abstractions for defining data structures and working with data. However, I have received a few queries for a DynamoDB template for my project builder Goldstack and I figured a

amazon-route-53
AWS S3 has long been known as an effective way to host static websites and assets. Unfortunately, while it is easy to configure an S3 bucket to enable static file hosting, it is quite complicated to achieve the following: * Use your own domain name * Enable users to access the content

aws
AWS S3 is a cloud service for storing data using a simple API. In contrast to a traditional database, S3 is more akin to a file system. Data is stored under a certain path. The strengths of S3 are its easy to use API as well as its very low

aws
Amazon Simple Email Service (SES) is a serverless service for sending emails from your applications. Like other AWS services, you can send emails with SES using the AWS REST API or the AWS SDKs. In this article, I want to look at how to send emails using SES with TypeScript

aws
Next.js 12 has been released a few months ago. It is a major update to the Next.js framework that includes a lot of new features and improvements. Goldstack provides two templates based on Next.js: Next.js Template for building vanilla Next.js applications Next.js + Bootstrap Template

aws
I has been nearly two years since I first wrote about a Next.js + Bootstrap starter project on this blog. Since then I have been extending the base template and made it easier to configure and use. It is now available as one of the templates on Goldstack: Next.js

aws
Terraform for better or worse is frequently updated with new versions. Many of these introduce incompatibilities with previous versions that require manual rework of Terraform definitions as well as require updating the local or remote Terraform state. I originally developed a solution for deploying Next.js to AWS using Terraform
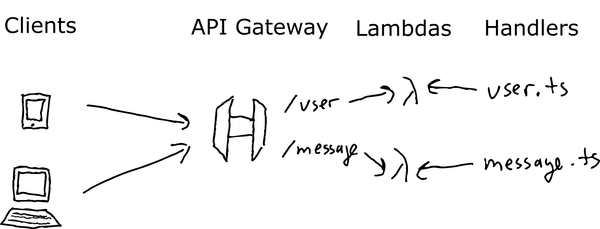
aws
There are many ways to stand up a REST API. Nearly every programming language provides a way for us to develop a simple web server, such as Express.js, Go Gin or Python Flask. However, with the advent of serverless computing, we need to rethink some of the fundamentals of
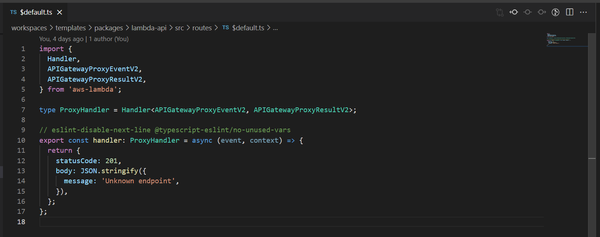
aws
TypeScript is an excellent language for writing AWS Lambda functions. Its flexible static typing allows for high developer productivity and since it can be transpiled into JavaScript, our code can be bundled into small deployment packages that allow for fast Lambda cold starts, without need for keeping 'warm'

aws
I've written a couple of posts about how to set up JavaScript and TypeScript Monorepos over the past three years (#1, #2, #3, #4, #5, #6, #7), and I kind of thought I had it all figured out - but I didn't. It turned out that